- español
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Cómo funcionan los dispositivos IoT: arquitectura, componentes y factores de rendimiento
Catálogo
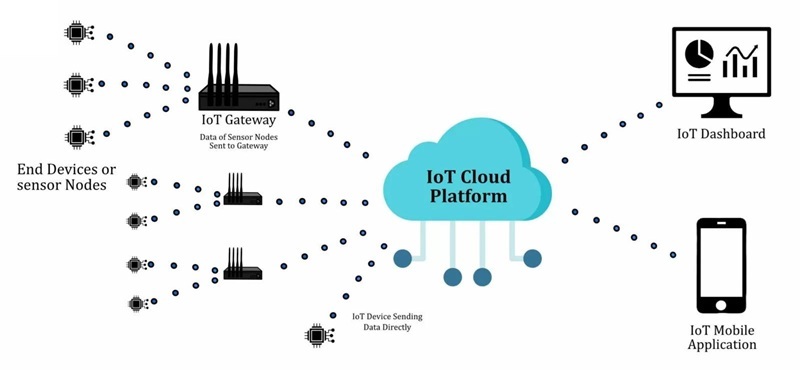
Cómo funciona un dispositivo IoT
Un producto IoT es más fácil de entender cuando se trata como un bucle cerrado y medible: observa el mundo físico, convierte lo que ha observado en datos que la electrónica puede manejar, mueve esos datos a un lugar donde pueden ser interpretados y luego desencadena una respuesta. Muchos equipos comienzan persiguiendo la "conectividad", y es comprensible, las demostraciones se ven geniales cuando el panel de control se actualiza en tiempo real, pero en el campo, el dispositivo se juzga por si se comporta de la misma manera en el día 3, el día 30 y el día 300.
El bucle tiene que sobrevivir a las limitaciones cotidianas que tienden a aparecer en los peores momentos: energía limitada, latencia impredecible, interferencias, techos de costo y expectativas de seguridad en evolución. Cuando el bucle se diseña teniendo en cuenta esas limitaciones, las capas de red y cloud se sienten como una extensión limpia del producto en lugar de una fuente de sorpresas y casos extremos frágiles.
Sensar: Convertir una señal física en una eléctrica
En el borde, un sensor convierte una variable del mundo real en una representación eléctrica que el dispositivo puede medir. La variable puede ser ambiental, mecánica o eléctrica, y el trabajo del sensor es crear una señal que siga siendo interpretable a través de cambios de temperatura, vibración y variabilidad de instalación.
Variables del mundo real comúnmente medidas:
• Temperatura
• Vibración
• Presión
• Luz
• Movimiento
• Corriente
• Concentración de gas
La salida del sensor típicamente cae en uno de dos grupos, y la elección afecta todo lo que está aguas abajo (diseño de front-end, muestreo y tolerancia al ruido).
Tipos comunes de salida de sensor:
• Analógica: un voltaje o corriente que varía continuamente
• Digital: lecturas paquetizadas a través de I²C/SPI/UART
Fuera de condiciones de laboratorio, la precisión de la medición depende de más que del sensor mismo. Factores de instalación como la colocación, la fuerza de montaje, el flujo de aire, fuentes de calor cercanas, el enrutamiento de cables y el acoplamiento mecánico pueden afectar significativamente los resultados.
Los errores de medición a menudo son causados por problemas de instalación en lugar de fallos del sensor. Superficies de montaje flexibles o estructuras resonantes pueden distorsionar los datos y crear lecturas engañosas. Tratar el diseño de montaje y mecánico como parte del sistema de medición ayuda a reducir el tiempo de resolución de problemas y mejora la fiabilidad de las mediciones.
Condicionar: Frente Analógico (AFE) e Higiene de Señal
Muchos dispositivos dirigen las salidas en bruto del sensor a través de un frente analógico (AFE) antes de digitalizar. Esta etapa da forma silenciosamente a si el resto del sistema está trabajando con una señal estable y confiable o con algo que solo se comporta en condiciones controladas.
Funciones típicas del AFE:
• Polarización y generación de referencia para mantener las señales dentro del rango de entrada válido del ADC
• Amplificación (amplificadores de instrumentación, etapas de ganancia) para hacer que señales pequeñas sean medibles
• Filtrado (pasa-bajos, filtrado anti-aliasing) para reducir el ruido y limitar el contenido engañoso de alta frecuencia
• Protección (estructuras ESD, protección contra sobretensiones, clamps de entrada) para sobrevivir a errores de cableado y manipulación
Los entornos operativos reales a menudo introducen fuentes de ruido como motores, cables largos, reguladores de conmutación y radios cercanos. Estos efectos pueden crear errores de medición que pueden parecer aleatorios hasta que se identifica la fuente.
Una buena puesta a tierra, un apantallamiento adecuado y un filtrado anti-aliasing básico a menudo mejoran la calidad de la señal de manera más efectiva que depender únicamente de un filtrado de software complejo. Abordar el ruido en la fuente suele producir mediciones más fiables y un mejor rendimiento del sistema.
Convertir: Muestreo ADC con compromisos intencionados
Cuando la señal es analógica, un ADC la convierte en muestras digitales. La conversión en sí es sencilla; lo que tiende a requerir experiencia es elegir parámetros de muestreo que se comporten bien bajo los límites reales de la batería y la red.
Dos opciones de muestreo que dan forma al comportamiento posterior:
• Tasa de muestreo: lo suficientemente rápida como para capturar el fenómeno, pero no tan rápida que consuma energía y produzca datos innecesarios
• Resolución: lo suficientemente fina como para detectar cambios significativos sin convertir el ruido y la deriva en precisión falsa
El muestreo funciona mejor cuando se trata como una decisión a nivel de sistema en lugar de una especificación aislada. El sobremuestreo puede forzar silenciosamente más actividad de radio (y el tiempo de radio es a menudo lo que agota la batería primero). El submuestreo puede perder eventos breves operativamente significativos, picos de presión, impactos, paradas breves, que los usuarios recuerdan porque fueron el momento en que algo salió mal.
Calcular: Procesamiento de microcontroladores, sincronización y lógica de borde
Un microcontrolador (MCU) típicamente lee datos de sensores en un horario disciplinado usando temporizadores, interrupciones y DMA para que la sincronización del dispositivo se mantenga constante incluso cuando el firmware crece. La sincronización constante es uno de esos detalles que parece aburrido hasta el día en que estás depurando un problema en el campo y te das cuenta de que la "señal" era en realidad la fluctuación del cronograma.
Tareas comunes de procesamiento del lado de la MCU:
• Filtrado digital (promedio móvil, mediana, IIR) para reducir la fluctuación y los valores atípicos
• Calibración y compensación (corrección de offsets, compensación de temperatura, linearización)
• Evaluación de reglas (umbrales, histéresis, rebote) para prevenir un cambio inestable
• Análisis ligero en el borde (extracción de características, puntuación de anomalías, compresión) para reducir el ancho de banda y la computación en la nube
Un enfoque de diseño útil es separar los datos de medición de la lógica de decisión. Las lecturas de los sensores pueden fluctuar debido a condiciones físicas normales, mientras que un comportamiento estable del sistema puede mantenerse mediante histéresis, ventanas de tiempo y control de máquinas de estado. Esta separación ayuda a reducir las falsas alarmas, mejora la estabilidad del sistema y previene indicaciones de fallos incorrectas cuando ocurren variaciones temporales en la medición.
No todas las decisiones se benefician de esperar en la nube. Algunas acciones son sensibles al tiempo o están orientadas a evitar daños, y retrasarlas fuera del dispositivo tiende a crear modos de fallo incómodos cuando la red es lenta o está ausente.
Ejemplos comúnmente manejados localmente:
• Corte por sobrecorriente; protección contra sobrecalentamiento; detección de estancamiento del motor
La nube tiende a brillar cuando la tarea se beneficia de un contexto más amplio o horizontes de tiempo más largos.
Categorías de decisiones del lado de la nube:
• Análisis de tendencias a largo plazo y mantenimiento predictivo
• Correlación entre dispositivos
• Actualizaciones de modelo y cambios de políticas en toda la flota
Una regla práctica en la que los equipos suelen converger es sencilla: si un comando retrasado podría plausiblemente causar daños, el dispositivo debería protegerse primero y reportar después. Ese enfoque suele sentirse conservador de una buena manera, especialmente cuando eres el que está de guardia durante una interrupción de la red.
Comunicar: Enlaces de radio/cableados y protocolos de aplicación
La capa de comunicación mueve telemetría a un teléfono, puerta de enlace o punto final en la nube. Seleccionar una tecnología de enlace tiene menos que ver con lo que está de moda y más con lo que se adapta al entorno físico, al modelo de implementación y al presupuesto de energía.
Opciones comunes de conectividad:
• Wi-Fi; BLE; Zigbee/Thread; celular (LTE-M/NB-IoT); Ethernet
Por encima de la capa de enlace, los dispositivos utilizan protocolos de aplicación para estructurar y entregar mensajes. El protocolo adecuado suele depender de si el producto necesita telemetría en streaming, flujos de trabajo de configuración o compatibilidad con la infraestructura empresarial existente.
Protocolos de aplicación comunes:
• MQTT
• HTTP
Las implementaciones reales rara vez ofrecen conectividad estable. Los puntos de acceso se reinician, las puertas de enlace desaparecen, la cobertura celular cambia y la interferencia va y viene. Los dispositivos parecen mucho más fiables cuando pueden almacenar datos en búfer, reintentar con moderación (no de una manera que sobrecargue la red) y mantener un comportamiento claro del último estado conocido, de modo que el sistema siga siendo comprensible cuando los enlaces son imperfectos.
La telemetría se protege típicamente con TLS para la confidencialidad y la integridad. En muchos productos, la primera victoria en seguridad es simplemente activar el cifrado en todas partes, pero la seguridad duradera va más allá al hacer que la identidad y las actualizaciones sean manejables durante toda la vida del dispositivo.
Elementos básicos de seguridad comunes:
• Identidades de dispositivos únicas y autenticación basada en certificados
• Almacenamiento seguro de claves (elementos seguros o zonas de confianza de MCU)
• Firmware firmado y arranque seguro para reducir la posibilidad de ejecución de código no autorizado
Hay un patrón que los equipos experimentados reconocen (a menudo después de aprenderlo de la manera difícil): el trabajo de seguridad es mucho menos doloroso cuando la identidad, la gestión de claves y los caminos de actualización se diseñan desde el principio. Cuando esos cimientos se planifican desde el comienzo, el dispositivo tiende a mantenerse utilizable durante años, no solo hasta la primera actualización mayor en el campo.
Nube y Datos
En la nube (o en una plataforma local), los datos se almacenan, a menudo en sistemas de series temporales, luego se agregan y analizan. La nube es donde la telemetría cruda puede convertirse en resultados sobre los que alguien realmente actuará, ya sea ese alguien un usuario, un operador o un motor de políticas automatizado.
Resultados comunes de la nube:
• Alertas (incumplimientos de umbral, detección de fallas)
• Predicciones (vida útil restante, detección de deriva)
• Tableros (KPI, tendencias, salud de flota/dispositivo)
• Comandos de control (puntos de ajuste, programaciones, acciones de habilitar/deshabilitar)
El valor de la nube es más fácil de capturar cuando los equipos deciden de antemano qué decisiones se supone que debe respaldar la data. Sin esa disciplina, la telemetría tiende a convertirse en un ruido de fondo costoso, recogido de manera fiable, almacenado con diligencia y luego raramente utilizado con confianza.
Actuar: Ejecutar Comandos de Manera Segura y Repetible
Los comandos enviados de vuelta al dispositivo activan los actuadores, y esta parte del bucle es donde la realidad del hardware se hace ruidosa. La activación requiere circuitos de control adaptados a la carga, y se beneficia de barandillas que hacen que las fallas sean predecibles en lugar de caóticas.
Actuadores comunes:
• Motores
• Válvulas
• Relés
• Calentadores
• LEDs
• Altavoces
Elementos comunes de controlador y protección:
• MOSFET; relés; puentes H; triacs (dependiendo de las características de la carga)
• Diodos de recuperación y snubbers (para cargas inductivas)
• Detección de corriente y protecciones térmicas
• Verificación de estado cuando está disponible (interruptores de límite, retroalimentación de posición, firmas eléctricas)
Una mentalidad de fiabilidad que tiende a dar resultado es asumir que la activación es donde se concentra el riesgo. Los sensores a menudo fallan silenciosamente; los actuadores pueden fallar de maneras que los usuarios notan de inmediato. Salvaguardias simples, tiempos de espera, interbloqueos y verificaciones de cordura, previenen frecuentemente problemas en cascada y hacen que el sistema se sienta más confiable durante los inevitables casos extremos extraños.
El Bucle Se Repite
Este ciclo de sentido; computar, comunicar, activar se repite continuamente. Localmente, puede ejecutarse en milisegundos; un viaje de ida y vuelta a la nube puede tardar segundos dependiendo de la red y la carga del backend. Los buenos productos tratan el tiempo y la energía como insumos de diseño que dan forma a cada otra decisión, en lugar de consideraciones de último momento que se optimizan al final.
Estrategias comunes a nivel de sistema:
• Utilizar procesamiento en el borde para reducir transmisiones innecesarias
• Agrupar y comprimir telemetría cuando la tolerancia a la latencia lo permite
• Dormir agresivamente y despertar de manera predecible en dispositivos con batería
• Mantener un "comportamiento mínimo viable" incluso cuando no se puede alcanzar la nube
Un dispositivo IoT duradero no se define por ningún componente único. Se define por la calma con la que se comporta todo el bucle cuando la realidad se desvía del plan: señales ruidosas, redes intermitentes, hardware envejecido y comportamiento de usuario impredecible. Diseñar con esas condiciones en mente es a menudo la diferencia entre una demostración que funciona una vez y un producto que mantiene su compostura año tras año.
Componentes Electrónicos en el Rendimiento de Dispositivos IoT
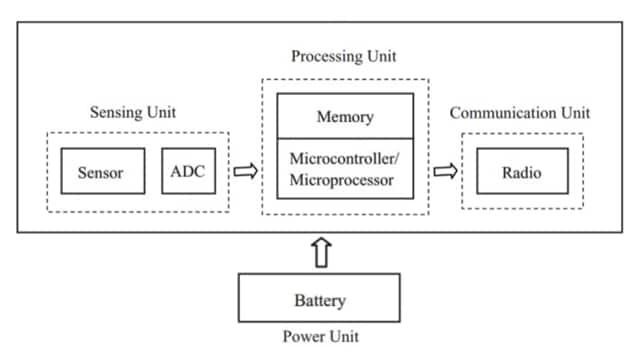
El hardware IoT tiende a sentirse fiable solo cuando las entradas del sensor, el procesamiento, el almacenamiento, la entrega de energía y la conectividad se configuran como un único camino continuo de señal y energía.
Una lectura de sensor rara vez se mantiene significativa si la tensión de referencia cambia, si el reloj presenta jitter, o si el camino de datos ocasionalmente pierde bytes bajo carga. Un enlace de radio rara vez se mantiene utilizable si la alimentación disminuye durante los estallidos de transmisión, si el oscilador es ruidoso, o si el manejo de credenciales es inconsistente entre reinicios.
Muchos equipos aprenden que la fiabilidad a menudo mejora más al ajustar los límites de bloque a bloque que al añadir otra característica: raíles predecibles, temporización limitada, acoplamiento de ruido controlado y un comportamiento de fallo que sea comprensible cuando algo se rompe.
El objetivo del diseño no es "piezas perfectas", sino interfaces que se comporten de la misma manera en un banco de desarrollo, en implementaciones piloto y meses después en el campo.
Sensor
Los sensores convierten las condiciones del mundo real en señales eléctricas, pero el comportamiento del producto día a día se define por detalles que pueden parecer pequeños hasta que los datos del campo los hacen sentir incómodamente grandes.
El ruido, la deriva, el montaje, el flujo de aire, la condensación y el enrutamiento de cables tienen una forma de convertir un gráfico limpio de laboratorio en distribuciones desordenadas que el firmware debe sobrevivir.
El rango y la resolución deben ajustarse a la decisión que se está tomando, no a una especificación titular. Las configuraciones excesivamente sensibles a menudo amplifican el ruido y la deriva, lo que tiende a aumentar los falsos positivos y aumenta silenciosamente el tiempo de cómputo y el tiempo de aire de radio. Un rango lo más ajustado posible puede parecer defendible durante las revisiones de diseño, sin embargo, el comportamiento en el campo a menudo favorece un rango ligeramente más amplio que produce mediciones más estables y más interpretables. Si un modelo de downstream o umbral va a suavizar los datos de todos modos, empujar la sensibilidad bruta demasiado lejos puede sentirse satisfactorio al principio y luego frustrante cuando llegan los tickets de soporte.
La deriva, el envejecimiento y la exposición determinan si las mediciones siguen siendo creíbles después de meses o años.
La calibración generalmente funciona mejor cuando se trata como una rutina de ciclo de vida en lugar de un solo ritual de fábrica que todos esperan que se mantenga para siempre.
• Calibración de fábrica con coeficientes almacenados.
• Disparadores de recalibración en campo (programados, basados en eventos o asistidos por técnicos).
• Rutinas de auto-verificación que marcan valores atípicos, recortes y saturaciones.
Los equipos que buscan productos reparables a menudo reservan modestas capacidades de flash y computación para metadatos de calibración, trazabilidad y comprobaciones de sensatez, porque es más barato que explicar lecturas inconsistentes después del despliegue.
La selección de la tasa de muestreo suele ser una negociación entre la física, la batería y la utilidad de los datos. Muestrear demasiado lentamente arriesga el aliasing y los eventos perdidos, lo que puede ser difícil de diagnosticar porque los datos aún parecen plausibles. Muestrear demasiado rápido aumenta el consumo de energía y el volumen de datos, y puede crear la ilusión de una mejor visión sin mejorar materialmente las decisiones.
Un patrón que se sostiene bien es capturar el fenómeno con suficiente margen, filtrando pronto (analógico cuando realmente ayuda, digital cuando es suficiente) y submuestreando para el informe.
Esto a menudo produce mejores resultados de batería que muestrear agresivamente y esperar que la analítica en la nube compense más tarde.
Si un ADC externo es justificable, generalmente depende de la resolución, la impedancia de entrada, la estabilidad de referencia y la tolerancia al ruido. Los ADC integrados en MCU suelen funcionar bien para la detección de media resolución, mientras que las señales de precisión tienden a castigar las decisiones casuales de diseño y referencia.
• Selección y enrutamiento de referencia de bajo ruido.
• Estrategia de puesta a tierra, trazas de guardia y control de camino de retorno.
• Apantallamiento y enrutamiento intencionado de cables cerca de los conectores.
• Protección ESD colocada donde realmente intercepte la transitoria.
Pequeños cambios en la PCB pueden reducir mediblemente el jitter y mejorar la repetibilidad, especialmente para fuentes de alta impedancia o señales analógicas de bajo nivel donde "casi bien" se vuelve visiblemente inestable en los datos de producción.
Microcontrolador (MCU)
El MCU actúa como el centro operativo: lee sensores a través de GPIO, I²C, SPI y UART; condiciona señales; ejecuta inferencias donde sea aplicable; gestiona modos de potencia; y controla salidas.
Cuando el comportamiento del MCU es predecible, todo el dispositivo se siente tranquilo; cuando no lo es, las fallas tienden a parecer aleatorias incluso cuando la causa es determinista.
El firmware estable generalmente proviene de máquinas de estado explícitas y tiempos que tienen límites claros. Los diseños impulsados por eventos utilizando interrupciones, DMA y temporizadores generalmente superan a los bucles de sondeo en capacidad de respuesta y energía, especialmente en dispositivos que duermen a menudo.
Cuando los equipos describen bloqueos aleatorios, el culpable es frecuentemente uno de unos pocos reincidentes: trabajo no acotado dentro de una interrupción, bloqueo de bus compartido, inversión de prioridades, o fragmentación de memoria que nunca se probó bajo largos períodos de actividad.
La planificación de RAM y flash funciona mejor cuando incluye lo que sucede después de que la primera demo tiene éxito.
• Buffers de red y sobrecarga de TLS (incluyendo el comportamiento de apretón de manos en el peor de los casos).
• Registros, métricas y volcado de errores que los ingenieros pedirán más tarde.
• Espacio de ensayo OTA, además de metadatos para comprobaciones de integridad.
• Ampliación de características que llega predeciblemente tras los comentarios del piloto.
La memoria de tamaño insuficiente a menudo permanece tranquila al principio y luego se vuelve dolorosa más tarde, justo cuando los diagnósticos y la seguridad de las actualizaciones se convierten en las principales herramientas para controlar el riesgo en el campo.
Los dispositivos que se espera sean de confianza suelen beneficiarse de arranque seguro, almacenamiento de claves protegido, aceleración criptográfica de hardware y un generador de números verdaderamente aleatorio. A partir de la experiencia de implementación, las adaptaciones de seguridad tienden a ser incómodas porque chocan con las limitaciones del hardware enviado y las credenciales de larga duración.
Seleccionar un MCU (o agregar un elemento seguro) que soporte una identidad fuerte y arranque medido a menudo reduce la cantidad de software ingenioso necesario para compensar raíces de confianza débiles.
El acceso para SWD/JTAG y la capacidad de prueba práctica suelen decidir si la fabricación temprana es controlada o caótica.
• Planificación del acceso SWD/JTAG y estrategia de bloqueo para la producción.
• Patas de prueba y diseño amigable para sondas para accesorios de alto volumen.
• Puntos de sentido de riel de energía y nodos medibles para un rápido diagnóstico.
Una pequeña cantidad de infraestructura de prueba puede ahorrar a los equipos semanas de incómodas conjeturas cuando el primer lote grande expone casos límite que nunca aparecieron en prototipos hechos a mano.
Módulos de Comunicación
El módulo de comunicación moldea más que el presupuesto de enlace: influye en la provisión, el comportamiento de actualización, los flujos de trabajo de soporte y una sorprendente cantidad de modos de fallo.
En dispositivos con batería, el comportamiento de radio a menudo domina el consumo de energía, por lo que las decisiones de conectividad tienden a convertirse en decisiones de duración de batería disfrazadas.
La selección suele equilibrar rango, latencia, rendimiento, topología y presupuesto de energía, con una mirada franca a la fricción operativa.
• BLE para rango corto, bajo consumo y puesta en marcha con smartphone.
• Wi‑Fi para mayor rendimiento con mayor corriente pico y demandas más estrictas de integridad de energía.
• Thread/Zigbee para redes en malla y despliegues de bajo consumo en casa/industrial.
• LoRaWAN para largo alcance, bajas tasas de datos y estricta disciplina de carga útil.
• LTE‑M/NB‑IoT para cobertura de área amplia con restricciones de operador y provisión más compleja.
Los equipos a menudo sienten alivio una vez que admiten que "la elección de la radio" es inseparable de la estrategia de reintento de firmware, manejo de corriente pico y la paciencia del usuario durante la configuración.
Un módulo fuerte aún puede decepcionar si la antena está mal colocada, desintonizada por el recinto o expuesta a retornos de tierra ruidosos.
• Zonas de exclusión para antenas y enrutamiento de impedancia controlada.
• Efectos del recinto y pruebas de interacción del usuario.
• Comprobaciones de emisiones radiadas y sondeo de susceptibilidad.
Cuando el margen de enlace es estrecho, los reintentos de firmware pueden enmascarar el síntoma por un tiempo, pero el costo de la batería se acumula de una manera que los equipos de operaciones notan mucho antes de que los ingenieros lo vean en un laboratorio.
El diseño de conectividad tiene que sobrevivir a flujos de trabajo reales en lugar de a demostraciones ideales.
• Provisión que tolere fallos parciales y errores comunes de los usuarios.
• Lógica de retroceso y reintento que evite espirales de drenaje de batería auto infligidas.
• Comportamiento de itinerancia más gestión del ciclo de vida de SIM/eSIM para dispositivos celulares.
• OTA con autenticación, reversión y programación consciente del ancho de banda.
OTA funciona menos como una característica brillante y más como un canal de mantenimiento a largo plazo; cuando se trata de manera casual, los dispositivos tienden a volverse costosos de soportar, incluso si el primer lanzamiento parece bien.
Gestión de Energía
El diseño de energía mantiene el dispositivo vivo, repetible y aburrido, en el mejor sentido de la palabra. Abarca reguladores, carga, medición de combustible, conmutación de carga y elecciones de protección que deben manejar tanto eventos de corriente pico como expectativas de sueño profundo.
La selección de Buck/boost/LDO se beneficia de evaluar la eficiencia en todo el rango completo de carga, no solo en un solo punto de operación. La corriente de reposo en modo de sueño a menudo decide si un producto cumple con las expectativas de la batería.
Las radios pueden crear picos de corriente agudos; la capacitancia de bulto, el enrutamiento de baja impedancia y los lazos de control estables tienden a decidir si el sistema se mantiene activo durante los estallidos de transmisión. Muchos reinicios misteriosos terminan rastreándose hasta caídas transitorias en lugar de firmware, lo que puede ser una lección humillante pero útil durante la integración.
La vida de la batería se gana comúnmente durante el sueño, donde pequeñas fugas se combinan en pérdidas medibles.
• Configuración de sueño profundo con solo las fuentes de activación que se utilizan realmente.
• RTC o temporizadores de bajo consumo para activaciones periódicas.
• Interrupciones GPIO o de sensores para activaciones impulsadas por eventos.
• Gating de energía para sensores y periféricos que no necesitan sesgo continuo.
Medir el sueño actual pronto en hardware real, y luego tratar los aumentos inesperados de microamperios como errores, tiende a prevenir el lento deslizamiento donde muchos bloques "casi apagados" erosionan silenciosamente el tiempo de ejecución.
La elección del IC de carga depende de la química, los límites térmicos, las restricciones regulatorias y el entorno esperado. La selección del medidor de combustible debe reflejar las necesidades de precisión a través de la temperatura, la carga y el envejecimiento. Para implementaciones al aire libre o no calentadas, el comportamiento a baja temperatura a menudo se convierte en el motor de la calidad percibida, por lo que los umbrales de voltaje conservadores y la información honesta de capacidad reducen las quejas de apagones abruptos.
El sobrecorriente, el sobrevoltaje, la polaridad inversa y el comportamiento ESD deben ser tratados como condiciones operativas rutinarias en muchas implementaciones. Los entornos industriales suelen producir eventos de descarga por cable y transitorios inductivos que pueden parecer "mala suerte" a menos que el diseño los anticipe. Los abrazaderas apropiadas, fusibles, diodos TVS, control de inrush y decisiones de aislamiento a menudo deciden si un dispositivo sobrevive su primer mes con una reputación intacta.
Componentes de Almacenamiento
El almacenamiento conserva firmware, configuración, certificados y registros. La elección entre flash NOR/NAND, EEPROM, FRAM, eMMC o microSD tiende a estar impulsada por la durabilidad, el rendimiento, el costo de BOM y cuán dolorosa sería una escritura corrupta operativamente.
Los dispositivos reales enfrentan caídas de tensión, reinicios del watchdog y escrituras parciales.
• Sumas de verificación o CRCs para configuración y registros.
• Nivelación de desgaste o frecuencia de escritura limitada para medios basados en flash.
• Registro o registros de solo anexado para datos que no pueden ser escritos a medias.
Un patrón operativo frecuente es el registro en búfer circular con tasas de escritura limitadas, que limita el consumo silencioso de durabilidad mientras deja suficientes migas de pan para depurar problemas en el campo.
Los espacios de firmware A/B más la lógica de arranque verificado y retroceso proporcionan una red de seguridad práctica durante actualizaciones interrumpidas. Sin estas salvaguardas, una única pérdida de energía durante una actualización puede dejar a los dispositivos varados en el campo. Los productos que escalan suavemente tratan típicamente la recuperabilidad en el mismo nivel que las características de envío, porque los costos de soporte tienden a seguir la calidad de la historia de recuperación.
Los certificados y claves deben almacenarse con resistencia a manipulaciones y control de acceso en mente, no simplemente en algún lugar no volátil. Incluso con almacenamiento seguro, los planes para rotación de claves, revocación y respuesta a incidentes reducen la exposición prolongada cuando una credencial se filtra o una flota se ve parcialmente comprometida.
Componentes de Interfaz
LEDs, pantallas, botones, micrófonos, cámaras y sensores biométricos modelan la usabilidad, pero también consumen energía, riesgo de EMI y consideraciones de privacidad. Una interfaz de usuario que se siente consistente bajo estrés a menudo refleja un diseño eléctrico disciplinado más que el pulido de la interfaz.
Los botones tienden a necesitar desbordamiento y protección ESD para evitar lecturas esporádicas incorrectas.
Los micrófonos y cámaras tienden a necesitar vías limpias y aterrizaje cuidadoso para evitar artefactos intermitentes que los usuarios interpretan como "inestables".
• Separación de caminos analógicos sensibles de caminos de conmutación de alto corriente y RF.
• Planificación de caminos de retorno para limitar el acoplamiento de ruido.
• Elecciones de blindaje y filtrado que coincidan con la estrategia de caja y cable.
Las fallas intermitentes de la interfaz de usuario son frecuentemente causadas por acoplamiento de radios o motores, y puede ser sorprendentemente satisfactorio solucionarlas con disciplina de diseño y aterrizaje en lugar de interminables soluciones de firmware.
Los dispositivos se comportan de manera más predecible cuando tienen una historia fuera de línea que no depende de que la red esté disponible.
La retroalimentación local clara (estados de LED inequívocos y señalización de error mínima y precisa) tiende a reducir la carga de soporte y evita la frustración del usuario que proviene de un comportamiento de falla silencioso.
Actuadores
Los actuadores convierten la intención de control en movimiento, calor o fuerza, y suelen requerir circuitería de interfaz más allá de un pin MCU directo. Debido a que los actuadores interactúan con el mundo físico, los modos de falla tienden a ser visibles, costosos y emocionalmente escalatorios para los usuarios. Motores, solenoides, válvulas y relés comúnmente necesitan etapas MOSFET, puentes H o ICs de controlador dedicados dimensionados para corrientes y transitorios reales.
• Diodos de recuperación o snubbers para cargas inductivas.
• Detección de corriente para la detección de atascos y respuesta a sobrecargas.
• Consideraciones de diseño térmico para cargas continuas o de alta duración.
La experiencia en el campo a menudo muestra problemas relacionados con los actuadores como una fuente frecuente de fallas, y la reducción conservadora más la detección de fallas tienden a mejorar el comportamiento de la flota de una manera que los equipos de soporte notan rápidamente.
Un dispositivo debe seguir siendo seguro cuando el firmware falla, la nube no es accesible o los comandos llegan tarde.
• Estrategia de watchdogs y reinicio alineada con salidas seguras.
• Estados de salida seguros por defecto definidos por cada actuador y por cada modo.
• Posiciones mecánicas de fail-safe donde la aplicación lo exige.
Los diseños más resilientes tratan la pérdida de conectividad como un modo de operación normal y definen exactamente lo que hace el actuador durante ese período, por lo que el comportamiento se mantiene predecible incluso cuando todo lo demás es imperfecto.
Integración a Nivel de Sistema
Las mejoras de alto impacto a menudo provienen de prácticas de integración que obligan a todo el sistema a decir la verdad desde el principio.
• Validación de la integridad de la energía bajo las peores condiciones de carga de radio y actuadores.
• Control de ruido a través de sensores analógicos, reguladores de conmutación y controladores de alta corriente.
• Flujos de arranque, actualización y recuperación con estados medibles y observabilidad clara.
• Pruebas ambientales (temperatura, humedad, vibración) elegidas para coincidir con las condiciones de despliegue reales.
Cuando estas actividades se tratan como trabajo de ingeniería diario en lugar de una ceremonia de etapa final, las elecciones de componentes suelen volverse menos dramáticas, y el comportamiento del dispositivo tiende a permanecer consistente desde el prototipo hasta el despliegue masivo.
Conclusión
Los sistemas IoT exitosos dependen de un bucle de datos completo y confiable que incluye detección, acondicionamiento de señal, procesamiento, comunicación, seguridad y gestión de energía. Cada etapa afecta el rendimiento general, la vida útil de la batería, la precisión y la experiencia del usuario. Al equilibrar el hardware, el firmware, la red y las limitaciones operativas, los dispositivos IoT pueden ofrecer monitoreo, control y automatización confiables en una amplia gama de aplicaciones.
Preguntas Frecuentes [FAQ]
1. ¿Por qué muchos proyectos de IoT fallan por problemas de calidad de medición en lugar de problemas de conectividad?
La conectividad a menudo recibe la mayor parte de la atención durante el desarrollo porque los paneles de control y las integraciones en la nube son altamente visibles. Sin embargo, las mediciones inexactas causadas por una mala colocación del sensor, vibraciones, efectos del flujo de aire, acoplamiento térmico, ruido o errores de instalación pueden socavar todo el sistema. Si los datos originales son poco confiables, incluso las analíticas más avanzadas, las plataformas en la nube y las redes de comunicación no pueden producir decisiones confiables. El éxito a largo plazo de IoT generalmente comienza con mediciones estables en lugar de características de conectividad sofisticadas.
2. ¿Por qué debería considerarse la colocación de sensores como parte del propio sistema de detección?
Los sensores miden condiciones físicas a través de su interacción con el entorno circundante. La fuerza de montaje, el diseño del recinto, el enrutamiento de cables, el flujo de aire, la transferencia de vibraciones y el contacto térmico pueden alterar lo que percibe el sensor. Un sensor perfectamente calibrado puede aún así producir lecturas engañosas si está montado de manera inadecuada. En muchos despliegues, los errores relacionados con la instalación contribuyen a más incertidumbre de medición que las especificaciones del sensor, lo que hace que la integración mecánica sea una parte crítica del rendimiento general de detección.
3. ¿Por qué el muestreo excesivo es a menudo una amenaza oculta para la vida útil de la batería en dispositivos IoT?
Muestrear datos con más frecuencia de la necesaria aumenta la carga de procesamiento, el uso de memoria y la actividad de comunicación. Dado que la transmisión inalámbrica es frecuentemente el mayor consumidor de energía en productos IoT alimentados por batería, recopilar datos excesivos puede aumentar indirectamente el uso de radio y acortar el tiempo de funcionamiento. Aunque altas tasas de muestreo pueden parecer mejorar la precisión, a menudo crean conjuntos de datos más grandes sin ofrecer mejoras significativas en la calidad de decisión. Estrategias de muestreo efectivas equilibran los requisitos de detección de eventos con el consumo de energía y las necesidades de informes.
4. ¿Por qué los dispositivos IoT exitosos separan la lógica de medición de la lógica de toma de decisiones?
Los valores crudos de los sensores fluctúan naturalmente debido al ruido, la variación ambiental y el comportamiento normal del proceso. Si cada medición desencadena directamente una acción, los sistemas pueden volverse inestables y generar falsas alarmas. Al separar la recolección de medidas de la lógica de decisiones mediante histéresis, máquinas de estado, filtrado, ventanas de tiempo y reglas de validación, los dispositivos pueden seguir siendo receptivos mientras evitan reacciones innecesarias a fluctuaciones temporales. Este enfoque mejora la fiabilidad y crea un comportamiento de sistema más predecible en condiciones del mundo real.
5. ¿Por qué muchas decisiones críticas de IoT se procesan localmente en lugar de ser delegadas a la nube?
Los sistemas en la nube proporcionan un análisis a largo plazo valioso, gestión de flotas e información predictiva, pero los retrasos y cortes de red pueden hacerlos inapropiados para funciones de protección sensibles al tiempo. Eventos como condiciones de sobrecorriente, sobrecalentamiento, paradas de motores o apagados de seguridad a menudo requieren acción inmediata. Esperar la confirmación de la nube podría permitir que se produzcan daños a los equipos o condiciones inseguras. Por esta razón, las decisiones críticas de protección y control se ejecutan comúnmente en los extremos, mientras que las plataformas en la nube se centran en la monitorización y optimización.
Blog relacionado
-
¿Cuántos ceros en un millón, mil millones, billones?
![¿Cuántos ceros en un millón, mil millones, billones?]()
29/07/2024
Millones representan 106, una cifra fácilmente comprensible en comparación con los elementos cotidianos o los salarios anuales. Mil millones, equiva... -
Hoja de datos MOSFET IRLZ44N, circuito, equivalente, pinout
![Hoja de datos MOSFET IRLZ44N, circuito, equivalente, pinout]()
28/08/2024
El IRLZ44N es un MOSFET de potencia N-canal ampliamente utilizado.Reconocido por sus excelentes capacidades de conmutación, es muy adecuado para nume... -
Temperatura de la batería demasiado baja, la carga se detuvo.¿Cómo solucionarlo?
![Temperatura de la batería demasiado baja, la carga se detuvo.¿Cómo solucionarlo?]()
06/10/2024
Los problemas de carga de la batería del teléfono móvil son comunes, pero se pueden administrar de manera efectiva.La temperatura juega un papel im... -
Guía integral del transistor BC547
![Guía integral del transistor BC547]()
04/07/2024
El transistor BC547 se usa comúnmente en una variedad de aplicaciones electrónicas, que van desde amplificadores de señal básicos hasta circuitos ... -
Una guía completa para los multiplexores y su papel en los sistemas digitales
![Una guía completa para los multiplexores y su papel en los sistemas digitales]()
20/09/2025
Los multiplexores son componentes en sistemas digitales, diseñados para canalizar múltiples señales de entrada en una sola línea de salida utiliza... -
Guía integral para SCR (rectificador controlado por silicio)
![Guía integral para SCR (rectificador controlado por silicio)]()
22/04/2024
Los rectificadores controlados por silicio (SCR), o los tiristores, juegan un papel fundamental en la tecnología de electrónica de potencia debido a... -
LR621, SR621SW, 364, equivalentes y reemplazos de batería AG1
![LR621, SR621SW, 364, equivalentes y reemplazos de batería AG1]()
15/07/2024
Las baterías de botones LR621 y SR621SW prevalecen en dispositivos electrónicos compactos como relojes, juguetes pequeños, calculadoras y claves re... -
Fundamentos de los circuitos de operación
![Fundamentos de los circuitos de operación]()
28/12/2023
En el intrincado mundo de la electrónica, un viaje hacia sus misterios invariablemente nos lleva a un caleidoscopio de componentes de circuito, tanto... -
Comparación de diferencias y aplicaciones de NMOS y PMOS
![Comparación de diferencias y aplicaciones de NMOS y PMOS]()
15/11/2024
Comprender las diferencias entre los transistores NMO y PMOS es importante para diseñar circuitos eficientes.Los NMOS (tipo N-óxido-óxido-semicondu... -
CR2450 vs CR2032 Comparación: todo lo que necesita saber
![CR2450 vs CR2032 Comparación: todo lo que necesita saber]()
15/09/2025
Las baterías de los botones como CR2450 y CR2032 alimentan muchos productos electrónicos cotidianos, desde relojes y controles remotos hasta disposi...










Piezas calientes
- EP2C35F672C8N
- LC75394NED
- 08055U2R7BAT4A
- MM3Z10VT1G
- CGA5L3X8R2A334M160AD
- GRM1555C1E9R2CA01D
- D751543ZZQKRG1
- C2012X5R2A683K085AA
- BUF08822AIPWPRG4
- 12062C102KAT4A
- THS4222DGNRG4
- ADS7844NB
- PM400DSA060-01
- EPF10K50SQC240-2
- MCP9700AT-E/LT
- LSDVCD2000
- SC1166CSW.TR
- SC1185ASW
- MG50J6EL1
- DDC001TR
- 12101C682MAT2A
- C1005JB1V155M050BC
- RT8900GC
- FDB14N30TM
- LM22676MR-ADJ
- MB89097PFV-G-155-ERE1
- SMMBTA92LT1G
- TLV5610IYZR
- LT1871IMS-7
- CWR11KH685KC
- GRJ319R72A104KE11L
- AD9880KST-100
- LM2576S-ADJ
- ADS7846I
- WIN780P4FBI-166B1
- M61503FP
- SN75LBC241DW
- SP3239EEA-L
- RT0603DRE07165KL
- LM5166YDRCR
- MAX3232ECAE+
- XR68C192IJTR-F
- GWIXP465ADT
- M36W0R6040T8ZAQE
- MSD61988
- QCA6410-AL3C
- SDED5-002G-NCT
- TN80C196KC-20
- UPD7508G
- MC33PF8100EAES